What is Managed RAG with Gemini File Search?
A simplified, high-performance method for Voice AI data retrieval
Google’s Gemini File Search Tool acts as a hosted retrieval layer for voice agents. It automates chunking and indexing so developers can focus on agent behaviour rather than complex database maintenance.
Who is this Article for? | Article Use Case
This guide is for Voice AI Developers, Automation Engineers using Make.com or n8n, and technical agency owners who need to provide VAPI voice agents with accurate knowledge while reducing latency and token costs.
Why is traditional RAG becoming a bottleneck for voice agents?
Traditional Retrieval Augmented Generation (RAG) often requires too many moving parts, which leads to higher latency and costs. A standard setup involves a vector database like Pinecone, an embedding model from OpenAI, and custom logic to search and retrieve data.
Does multi-step RAG cause latency?
Yes. This multi-step process can introduce significant delays. Every additional step in a voice call increases the risk of a pause that feels unnatural to the user. Managing these separate services also adds to the monthly cost, as many vector databases charge for storage even when no queries are being made.

What is a Gemini File Search Store?
A Gemini File Search Store is a persistent, hosted retrieval engine that manages the technical aspects of RAG automatically. When you upload a document to this store, Google handles the parsing, chunking, and indexing.

How does automated indexing work?
The system automatically parses documents like PDFs or CSVs and breaks them into logical segments. It then indexes these segments for semantic search. Unlike temporary file storage, the File Search Store is persistent. Your data stays ready for retrieval indefinitely, making it a reliable choice for long-term project knowledge bases.
How does Managed RAG reduce token costs?
Managed RAG reduces costs by retrieving only the most relevant text chunks instead of processing an entire document. This logic is based on a pay-as-you-go model, where Google provides up to 1 GB of storage for free.

Can you optimise token usage?
The primary benefit is how the model handles data. Instead of reading an entire 50-page manual for every query, the tool retrieves only the specific sections needed. Tests show this can lead to a 60-75% reduction in token usage per request. This efficiency directly lowers the cost of running high-volume voice agents.
How do you connect VAPI to Gemini File Search?
Connecting a VAPI agent to Gemini File Search currently requires an orchestration layer like Make.com to act as an HTTP bridge. While the tool simplifies data retrieval, it is not yet a native "one-click" feature in most Voice AI dashboards.
What is the role of the HTTP bridge?
The HTTP bridge manages the communication between services. When a user asks a question, VAPI triggers a tool call. This call sends a request to Make.com, which then communicates with the Gemini API to retrieve the answer. This setup removes the need for a separate database but still requires a bridge to manage the data flow.
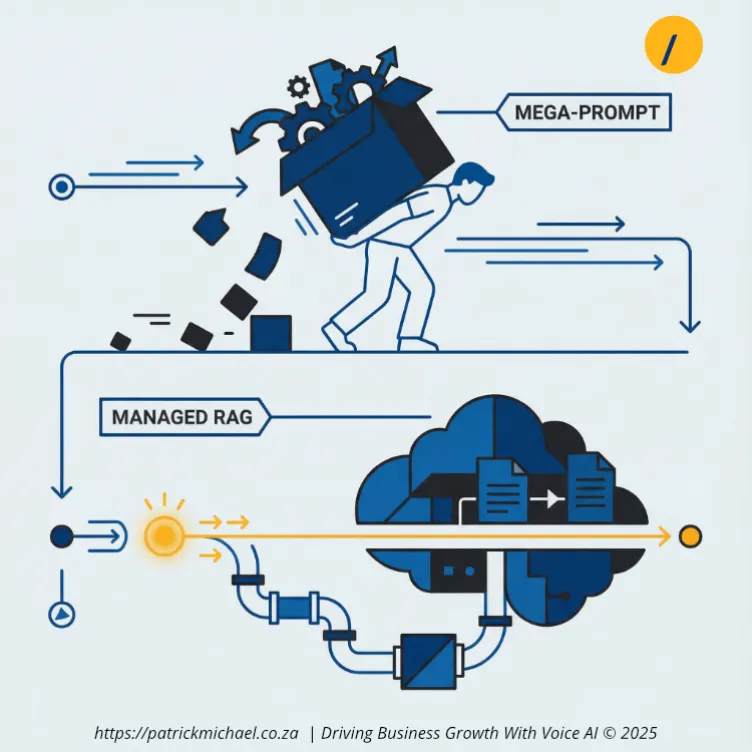
Is Managed RAG better than a "Mega-Prompt" strategy?
Yes. Managed RAG is superior to the "Mega-Prompt" strategy because it scales without increasing latency or cost. Many developers start by pasting an entire knowledge base into system instructions, but this method fails as data grows.
Why move beyond the Mega-Prompt?
As a knowledge base grows, a Mega-Prompt becomes expensive and slow. The model must process thousands of tokens before it can even begin to answer. The File Search Tool allows your knowledge base to grow to thousands of documents without impacting response time. The system remains fast because the model only interacts with the specific information it needs.
Conclusion
The Gemini File Search Tool is a practical option for developers who want to simplify their AI architecture. By moving the retrieval process into Google’s infrastructure, you can build agents that are faster, cheaper to operate, and easier to maintain. It provides a middle ground between simple prompts and complex custom-built databases.
TL;DR
- Managed Retrieval: Gemini File Search automates the chunking and indexing process.
- Lower Costs: Offers free storage up to 1GB and reduces tokens per query by 60-75%.
- Better Performance: Reduces latency compared to traditional multi-step RAG pipelines.
- Integration: Currently requires Make.com or n8n as an HTTP bridge for VAPI agents.
Article Resources
Links and downloads:
- TODO
Contact Me
I can help you with your:
- Voice AI Assistants;
- Voice AI Automation;
I am available for remote freelance work. Please contact me.
References
This article is made possible due to the following excellent resources:
- Gemini API File Search docs.
- Gemini API File Search API Reference
- Henryk Brzozowski: Comparative Analysis of Voice AI RAG Methods.
Recent Articles
The following articles are of interest:
Add new comment